
Data Science suffers from a very common newly-born sickness. It’s the unqualified pioneer problem, the Wild West of data science. No one knows how to correctly do data science, hence there are no fully accredited qualifications, hence no objective selection of potential data scientists in your company.
Hence, this post. Hence, you reading it. Ok. Let’s get started.
Let me ask you: would you let a knowledgeable, yet unexamined doctor do your cancer check-up? Imagine this doctor having lots of patients, day in, day out, however he manages to do that, and he claims he’s just getting better with each patient he’s treating. Does that sound trustworthy? (Spoiler: No!)
The same way you’d probably want some serious federal investigation going on with this non-doctor, you might not want an inexperienced data analyst working with your data. Maybe there’s some lonely guy up in the 7th building of some big company who recently finished his data science certificate on some website. Currently, he is desolately staring at your data and wondering what kind of method to use. Maybe on the 3rd floor of the very same building, there’s recruitment who are all hella happy to have acquired this new guy to support their data science team. And then, there’s you, sending your data to that company and hoping they won’t misuse it.
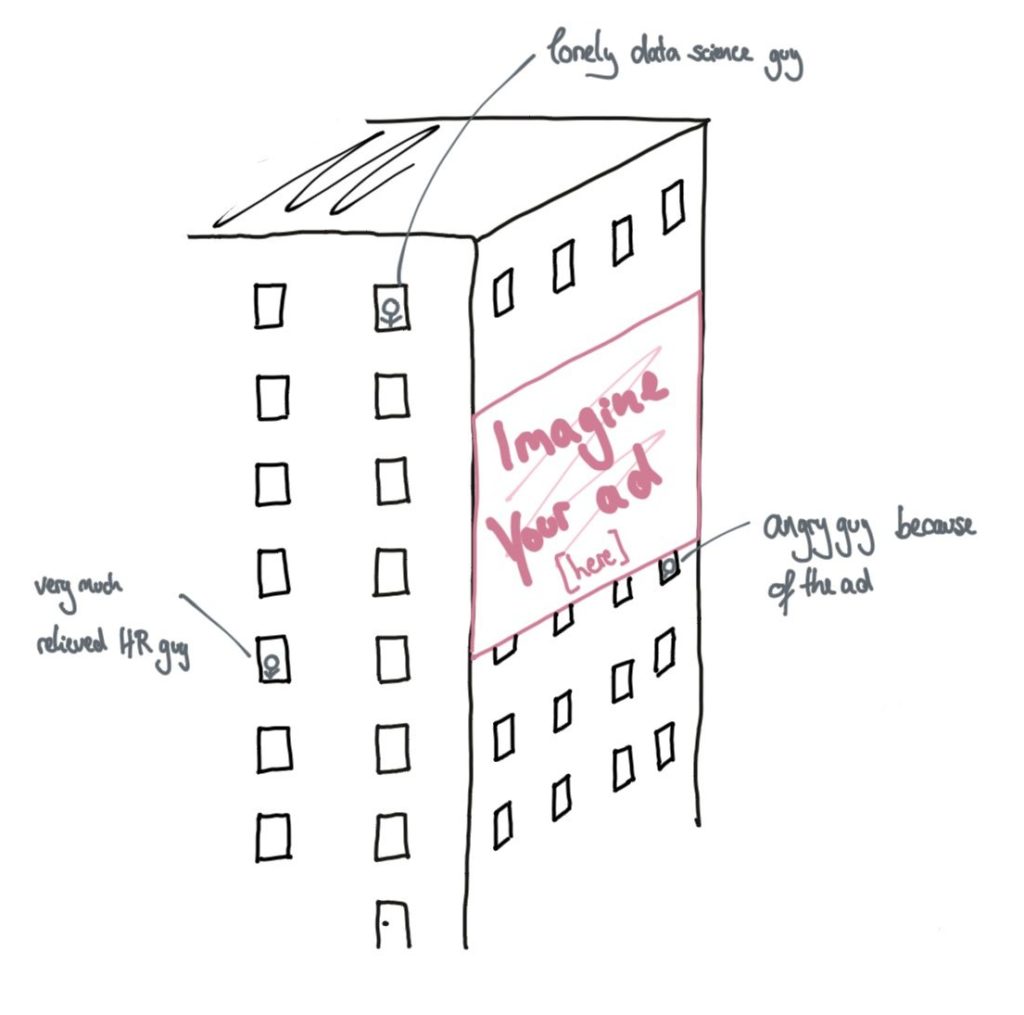
Chances are, the lonely guy doesn’t even know what to do with your data. On the other hand, he doesn’t know what to with it and might very well leak it, perform an inadequate type of analysis to it or perform things he isn’t even allowed to do (e.g. without proper anonymization).
According to contractualism, something is morally correct if both sides could have technically agreed to an action. This guy, willingly or not, violates a number of steps which we as original-data-perpetrators wouldn’t have agreed to. And that’s why my sleep at night would very much improve if there were more formal standards as to who analyzes my data! But I’m getting ahead of myself.
At this point, you might have two questions (at least I do):
1) What does “unqualified” data scientist mean?
2) What kind of bad things can even happen (yep, I spoiled that one above)?
3) Ok, what do we do now?
1) Let’s get our facts straight: What’s data science in the first place?
From my perspective, data science took a lot of math, in particular optimization and linear algebra, and mixed it with powerful computers, so to implement your algorithms, you’ll have to know some coding. Compared to statistics, methods from data science can take more features, more observations, do the more complicated models and predict more classes. Sounds like an upgrade to statistics? It isn’t.
Instead, Data Science offers a vast majority of methods, from network analysis to support vector machines and even neural networks. Most of them are supervised, meaning there is some interesting information such as a person’s happiness level waiting to be predicted. For this, there is a number of factors and an appropriate amount of rows taken into consideration.
First, classical statistics will fail at bigger data. If the sample size is big enough, there will be some people for whom a certain factor is significant. This means that classical statistics (well at least inferential statistics) and sample size (aka Big Data) exclude each other.
Second, in classical statistics, you might want to compare if two or more different groups of people significantly differ in their happiness level – that’d be a t-test or an ANOVA. Or if two factors really relate to each other – that’d be a correlation. Maybe even if there is a linear or even logistic way to predict our happiness level (linear and logistic regressions). But there will hardly be models capable to tackle more complex problems. What if I have text data? What if I am confronted with images?
That’s why Data Science isn’t an upgrade to existing statistics, it’s rather a richer set of features for different kinds of problems. Have bigger data? Don’t use inferential statistics. Want to predict something more complicated? Don’t use statistics. Want to do an old-fashioned statistical comparison? You know where to go to.
We as folks coming with a degree have probably discussed these methods, and I dare to say that with a little research, I’ll be able to estimate if a method is appropriate for a problem or not. The ones however that attended a five-day-course in Data Science or that did online courses for two months will not be able to choose from the pool of methods and correctly apply them.

2) So, what can even happen?
At this point, the lonely guy on 7th floor is probably applying some neural network to make sense of your recent emails to their support.
Let’s keep my criticism brief. Just that much: Neural networks won’t tell you why it got a certain result, so if you are classified into “unreliable”, only the neural network will know why. We call this the blackbox problem. Also, the neural network barely produces validated results that can be reproduced by other networks, the generalization problem (Gary, 2018). Without backed-up theory about the relations, how can we verify this data didn’t lead my neural network on the wrong path?
You being labelled as “unreliable” might therefore be incorrect, your data might be leaked, not secured or not even anonymized. To cite constructualism again, is this something you would hypothetically agree to? Probably not.
3) Ok, what do we do now?
In our emerging field of data science, we lack clear qualification guidelines and clear examinations. If we don’t know who is qualified because we don’t know it ourselves, we can hardly avoid people misusing data science methods and potentially endangering all its stakeholders. If unqualified people are allowed to deploy these methods, we cannot guarantee that the person examining your personal data knows what he’s doing.
Universities are only just starting to shape the field, and you may quickly gain the feeling you’re in some Western exploring the rough Wild West of data science.
Though we are this super shiny new field, we need to:
- clearly define what data science is (Kitchin, 2014; Schutt & O’Neil, 2013)
- clearly define who then is a data scientist
- offer clear ways to becoming an educated data scientist (like at Columbia, NY, or Leuphana, Germany)
- clearly define what degree of data science you should have acquired in order to work with such sensible data
- clearly brief recruiters
- and now, the hardest point: clearly define what may be done with data, to what degree of anonymization and to what extent of transparency
If you ask me, I do believe we’ll get to the point one day where we have narrowed down our definitions of Data Science. Our definitions of the Wild West.
Our lonely data scientist on 7th floor would have to adhere to these standards and despite of HR being incredibly happy to have someone doing data science, he’d have to first pass certain qualifications. We would then know (or at least hope) that he’ll employ the correct methods and treat our data well. This would create a world where I’d agree to what is done with my data. But up till then… be careful whom you’ll give access to your data.
– End of serious closing paragraph –
Are you longing to know about all the other (psychological) topics your data might encounter? Or desperate to tell me in the comments what other issues my data will face? Well, you’ve come to the right place, friend. I’m just getting started! But I’m looking forward to having you read all of my other upcoming short-ish posts on the entire chain of issues in psychological data science.